728x90
반응형
📌 KNN 알고리즘이란?
KNN(k-Nearest Neighbors)은 가장 직관적이고 간단한 머신러닝 알고리즘 중 하나로, 새로운 데이터가 주어졌을 때 가장 가까운 k개의 이웃 데이터를 기반으로 예측합니다. KNN은 분류(Classification)뿐 아니라 회귀(Regression) 문제에서도 사용할 수 있습니다.
🤔 KNN 회귀(KNN Regression)란?
KNN 회귀는 새로운 데이터의 주변 이웃 k개의 레이블 값을 평균(또는 가중 평균)하여 연속적인 수치 값을 예측하는 알고리즘입니다.
✅ 핵심 개념:
- 입력값과 가장 가까운 k개의 데이터를 찾음
- 이웃 데이터들의 target(출력) 값을 평균 냄
- 예측값으로 사용함
✅ 사용 시점:
- 데이터가 명확한 수치로 구성되어 있고, 복잡한 수학적 모델이 필요 없을 때
- 비선형 관계가 존재해도 단순한 방식으로 해결하고자 할 때
📊 예시: 광고 예산에 따른 판매량 예측
🎯 문제 상황:
마케팅 팀이 광고 예산을 얼마로 책정해야 할지 결정하고자 할 때, 과거 데이터를 기반으로 광고비를 투입하면 판매량이 얼마나 나올지 예측하고 싶다고 가정해봅시다.
✅ 입력 변수 (X): 광고비 (만원 단위)
✅ 출력 변수 (y): 판매량 (단위: 천 개)
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np
import matplotlib.pyplot as plt
# 가상의 데이터 생성
X = np.array([[10], [20], [30], [40], [50], [60], [70], [80], [90], [100]])
y = np.array([1, 2, 3, 4, 4.5, 5.5, 6, 7, 8, 9])
# 훈련/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# KNN 회귀 모델 생성 및 학습
knn_reg = KNeighborsRegressor(n_neighbors=3)
knn_reg.fit(X_train, y_train)
# 예측
y_pred = knn_reg.predict(X_test)
# 성능 평가
mse = mean_squared_error(y_test, y_pred)
print(f'MSE: {mse:.2f}')
# 시각화
plt.scatter(X, y, color='blue', label='Actual Data')
plt.scatter(X_test, y_pred, color='red', label='Predictions')
plt.xlabel('광고비(만원)')
plt.ylabel('판매량(천 개)')
plt.legend()
plt.title('KNN 회귀 예측 결과')
plt.show()🔍 결과 해석:
- k=3일 때, 가장 가까운 3개의 데이터의 평균을 예측값으로 사용
- 단순하지만 꽤 유용한 결과를 도출
🧠 다양한 회귀 알고리즘과 한계점 비교
머신러닝에서 사용되는 회귀 알고리즘은 다양하며, 각각의 장단점과 적용 가능한 상황이 다릅니다.
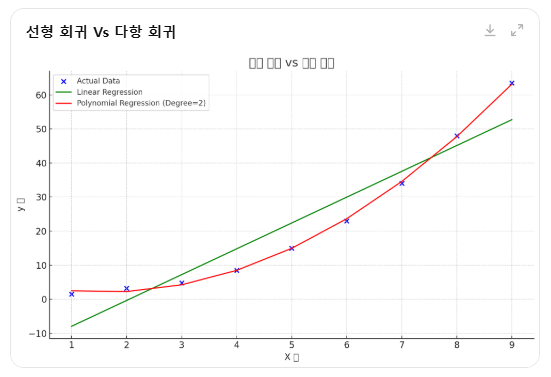
1. 선형 회귀 (Linear Regression)
- 📌 설명: 입력 변수와 출력 변수 간에 선형적인 관계가 있다고 가정하고, 데이터를 가장 잘 설명하는 직선을 찾는 모델입니다.
- ✅ 장점: 간단하고 빠르며 해석이 쉬움
- ❌ 한계: 데이터가 직선 관계일 때만 잘 작동
- 📌 예시: 광고비와 판매량이 완전히 비례하는 경우는 괜찮지만, 특정 포인트 이후 광고 효과가 떨어지면 정확도가 낮아짐
2. 다항 회귀 (Polynomial Regression)
- 📌 설명: 선형 회귀의 확장으로, 입력 변수의 제곱이나 세제곱 등의 고차항을 추가하여 비선형 관계를 모델링하는 방식입니다.
- ✅ 장점: 비선형 데이터도 일정 수준까지 설명 가능
- ❌ 한계: 고차항이 많아질수록 과적합 위험 증가, 해석이 어려워짐
- 📌 예시: 온도와 판매량이 포물선 형태로 관계가 있을 때는 유용하지만, 너무 많은 차수를 사용하면 실제 관계를 왜곡할 수 있음
3. 릿지 회귀 / 라쏘 회귀 (Ridge / Lasso Regression)
- 📌 설명: 선형 회귀의 변형으로, 과적합을 방지하기 위해 규제(regularization) 항을 추가한 모델입니다. 릿지는 L2 정규화, 라쏘는 L1 정규화를 사용합니다.
- ✅ 장점: 과적합 방지에 효과적 (정규화 기법 적용)
- ❌ 한계: 여전히 선형 모델이기 때문에 복잡한 비선형 문제에는 약함
- 📌 예시: 고차항 관계가 존재할 경우 성능 한계
4. KNN 회귀 (K-Nearest Neighbors Regression)
- 📌 설명: 입력 데이터와 가까운 k개의 이웃의 출력값 평균을 예측값으로 사용하는 비모수(non-parametric) 회귀 방식입니다.
- ✅ 장점: 비선형 데이터에도 유연하게 대응 가능
- ❌ 한계: 데이터가 많을수록 계산 비용이 커지고, 이상치에 민감함
- 📌 예시: 거리 기반이기 때문에 고차원 데이터에서는 성능 저하 발생
5. 의사결정트리 회귀 (Decision Tree Regression)
- 📌 설명: 데이터를 여러 개의 조건 분기로 나누어 예측값을 도출하는 트리 기반 회귀 모델입니다.
- ✅ 장점: 비선형 관계를 잘 모델링함, 해석이 쉬움
- ❌ 한계: 과적합(overfitting) 위험이 높음
- 📌 예시: 모든 데이터 포인트를 지나가려는 경향이 있어 테스트 데이터에는 성능 저하 가능
6. 랜덤포레스트 회귀 (Random Forest Regression)
- 📌 설명: 여러 개의 결정트리를 훈련시키고, 그 평균값을 사용하는 앙상블 회귀 모델입니다.
- ✅ 장점: 여러 트리를 앙상블하여 예측 정확도 향상
- ❌ 한계: 느리고, 모델 구조 해석이 어려움
- 📌 예시: 설명 가능한 모델이 필요한 상황에서는 부적절할 수 있음
7. SVR (서포트 벡터 회귀)
- 📌 설명: 서포트 벡터 머신(SVM)을 회귀에 적용한 방식으로, 마진 안의 오차는 무시하고 중요한 경계 데이터에 초점을 맞춥니다.
- ✅ 장점: 고차원에서도 잘 작동하며 다양한 커널 사용 가능
- ❌ 한계: 하이퍼파라미터가 많고, 대규모 데이터셋에서는 느림
- 📌 예시: 실시간 예측이 필요한 서비스에는 비효율적일 수 있음
💡 KNN 회귀 장단점
✅ 장점:
- 매우 직관적이고 구현이 쉬움
- 학습 시간이 거의 없음 (Lazy Learning)
- 비선형 문제에서도 유연하게 동작
❌ 단점:
- 데이터가 많을수록 계산 비용 증가
- 고차원 데이터에서는 거리 계산 정확도 저하 (차원의 저주)
- 적절한 k 값을 선택해야 함 (보통 교차검증 사용)
🔧 실무 팁
- StandardScaler를 사용해 정규화하면 거리 기반 알고리즘 성능 향상
- GridSearchCV로 k값 튜닝 가능
- 이상치가 많은 데이터에는 평균보다 가중 평균이 더 나을 수 있음
✅ 마무리 정리
KNN 회귀(KNN Regression)는 복잡한 수식 없이 가까운 이웃의 평균으로 값을 예측하는 간단하지만 효과적인 알고리즘입니다. 특히, 관측값이 적고 직관적인 모델이 필요할 때 유용합니다.
📢 실전 예제와 함께 KNN 회귀를 익혀보세요. 머신러닝 기초를 다지는 데 더할 나위 없는 좋은 출발점입니다. 구독하고 더 많은 AI/데이터 과학 콘텐츠 받아보세요! 🚀
반응형
'IT (IT)🤖🧠 > AI' 카테고리의 다른 글
| Cursor vs GitHub Copilot: AI 코드 도우미 비교 및 사용법 가이드 (0) | 2025.03.31 |
|---|---|
| 현실세계 다양한 문제해결을 위한 다중회귀 (0) | 2025.03.22 |
| 지도학습, 비지도학습, 강화학습의 차이점과 훈련세트 vs 테스트세트 완벽 정리 (0) | 2025.03.22 |
| k-Nearest Neighbors (KNN) 알고리즘과 Python 라이브러리 활용법 (0) | 2025.03.22 |
| 인공지능과 머신러닝 그리고 딥러닝 (0) | 2025.03.22 |